テキスト考 on ぷよクエ②
ぷよクエのキャラ(カード)の基本データには、画像、変身の演出、ヴォイスなどといったテキスト以外の部分もありますが、 最強デッキ選びにはほぼ関係ありません。 唯一ブーストエリア画像はポイントに関係しますが、これは後から何らかの形でテキスト化も可能なので、今回はスルーします。
そうすると、残るのは名称、コストを初めとする数値群、属性・タイプ・コンビといった性質群、 リーダースキル、スキル、スキル発動条件、とくもりというオプション的な性能アップということになります。
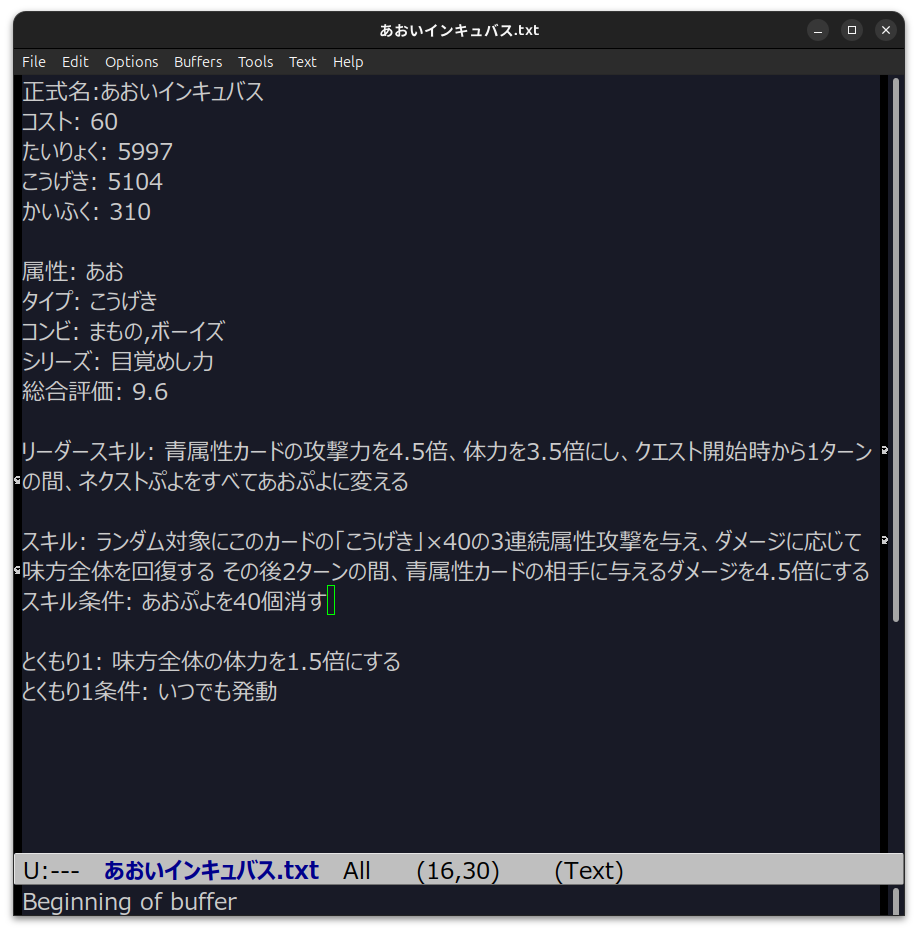
これらはゲーム内に自分がそのキャラを持っていれば確認できます。 しかし、それを見ながらコンピュータにデータを打ち込んでいく、それを 1000を超えるカードについてやるとしたら、1時間で 10キャラとすると……とてもやっていられません。 もっとましなのは、新キャラの概要はぷよクエ公式サイトに発表されるので、そのデータをコピー&ペーストする方法です。 時間は何分の一かになり、間違いも減るでしょう。 しかし、この方法ではずっと以前にリリースされたキャラのデータを取ってくるのが至難です。 結局、game8 でキャラを選択し(このページの左上の画像)、そこから各種データを拾うのが一番てっとり早そうです。
それにしても、ページを出し、データのある箇所までスクロールし、必要な部分をコピーし、所定のフォーマットに貼付けていくという、 一種退屈なルーチンを 1000キャラについて行うというのは大変です。 一日がかりの仕事になることは目に見えています。 何とかならないのでしょうか?
最強デッキを作るという観点からいけば、 【ぷよクエ】最強キャラクターランキングというページに記載のあるキャラデータを入手すれば ほぼ目的を達せられることがわかります。 さらに、ぷよクエ関連のページは以下のような形式の URL となっており、 問題になるページは、title 部に、【ぷよクエ】◯◯の評価とスキル・ステータス、という語句が含まれるものだとわかります。
https://game8.jp/puyoque/150905
ここまでくると、テキスト処理の独壇場です。 やり方はいろいろあるでしょう。 手順は次のようになります。
- 【ぷよクエ】最強キャラクターランキング のページをダウンロードする。
- ページのソースを開くと class="a-link" となっているリンク先にキャラクタの URL があることがわかるので、これを全て取り出す。
- ソートし、無関係なリンクを削除する。https://game8.jp/puyoque/ という部分をカット、150905 といった番号がダブっているので取り除く。
- wget などのツールを使い、https://game8.jp/puyoque/150905 のページを 150905.html として保存、これを 3.で入手した全番号について行う。
- 各ページから、このページの左上の画像にあるようなデータ形式で、各キャラのデータを取り出す。
簡単に説明します。1.は単純な保存なのでいいとして(1.html とする)、 2.は例えば次のような Perl スクリプト 2.pl を実行すればいいでしょう。
# perl 2.pl 1.html > 2.txt
while (<>) {
chomp;
while ($_ =~ /class="a-link" href="([^"]+)"/g) {
print "$1\n";
}
}
3. は emacs なら全体を選んで sort-lines というコマンドを実行、上下で https://game8.jp/puyoque/ を含まない行をカットし、uniq コマンドを実行、というようなプロセスです (詳しくはネットで検索してください)。
4. については短時間に大量のリクエストを送ることになるので、単に wget を for ループで回すのではなく、負荷を軽減するため、ウェイトを入れながら行う必要があると思います (例えば perl の中で sleep と system を使って wget を制御するなど)。 ここでは python の selenium モジュールを使う場合の例 4.py を書いておきます (実行には予め selenium モジュールをインポートし、セットしておく必要があります)。
#!/usr/bin/python3
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from time import sleep
import re
from selenium.webdriver.support.ui import WebDriverWait
chars = ['115078','119600']
options = Options()
UA = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
options.add_argument('--user-agent=' + UA) ## ユーザーエージェントの設定
options.add_argument('--no-sandbox') ## Sandboxの外でプロセスを動作させる
options.add_argument('--disable-dev-shm-usage')
browser = webdriver.Chrome(options=options)
for char in chars:
url = "https://game8.jp/puyoque/" + char
browser.get(url)
html = browser.page_source
log = open('log/' + char + '.txt', 'w')
print(html, file=log) # 一番簡単な形
log.close()
sleep(3)
browser.quit()
あらかじめスクリプトのあるディレクトリ下に log というサブディレクトリを作ってから実行します(python3 4.py)。 また、このままでは '115078', '119600' という 2キャラのページしか入手しないので、 動作を確認後、chars の配列部に 3. で作成した全キャラの番号を追加してやる必要があります。 これにより、log というディレクトリ下に、115078.txt, 119600.txt というようにデータがたまっていきます。
5. が最も難しいです。 しかし、処理に慣れるにつれ、少しずつ項目を増やしていけばいいので python の正規表現の扱いのいい練習かもしれません。
#!/usr/bin/python3
import re
import os
def get_info(filename):
html = ''
with open(filename) as f:
html = f.read()
name = ''
cost = 0
power = 0
attack = 0
recover = 0
attrib = ''
typeof = ''
m = re.findall(r'<title>【ぷよクエ】(.+?)の評価とスキル・ステータス', html, re.MULTILINE)
if m: name = m[0] #正式名
m = re.findall(r'<th class="center">コスト</th>.+?<td class="center">.+?<td class="center">(\d+)', html, flags=(re.MULTILINE|re.DOTALL))
if m: cost = m[0] #コスト
m = re.findall(r'<th class="center">たいりょく</th>.+?<td class="center">.+?<td class="center">(\d+)', html, flags=(re.MULTILINE|re.DOTALL))
if m: power = m[0] #たいりょく
m = re.findall(r'<th class="center">こうげき</th>.+?<td class="center">.+?<td class="center">(\d+)', html, flags=(re.MULTILINE|re.DOTALL))
if m: attack = m[0] #こうげき
m = re.findall(r'<th class="center">かいふく</th>.+?<td class="center">.+?<td class="center">(\d+)', html, flags=(re.MULTILINE|re.DOTALL))
if m: recover = m[0] #かいふく
m = re.match(r'.+?>タイプ</th>.+?(こうげき|たいりょく|バランス|かいふく)・', html, flags=(re.MULTILINE|re.DOTALL))
if m:
typeof = m.group(1) #タイプ
m = re.match(r'.+?属性</th>(.+?)>コンビネーション', html, flags=(re.MULTILINE|re.DOTALL))
if m:
tmp = m.group(1)
m = re.match(r'.+?(あか|あお|みどり|きいろ|むらさき)<.+?(あか|あお|みどり|きいろ|むらさき)<', tmp, flags=(re.MULTILINE|re.DOTALL))
if m: attrib = m.group(1) + '/' + m.group(2) #属性
else:
m = re.match(r'.+?(あか|あお|みどり|きいろ|むらさき)<', tmp, flags=(re.MULTILINE|re.DOTALL))
if m:
attrib = m.group(1) #属性
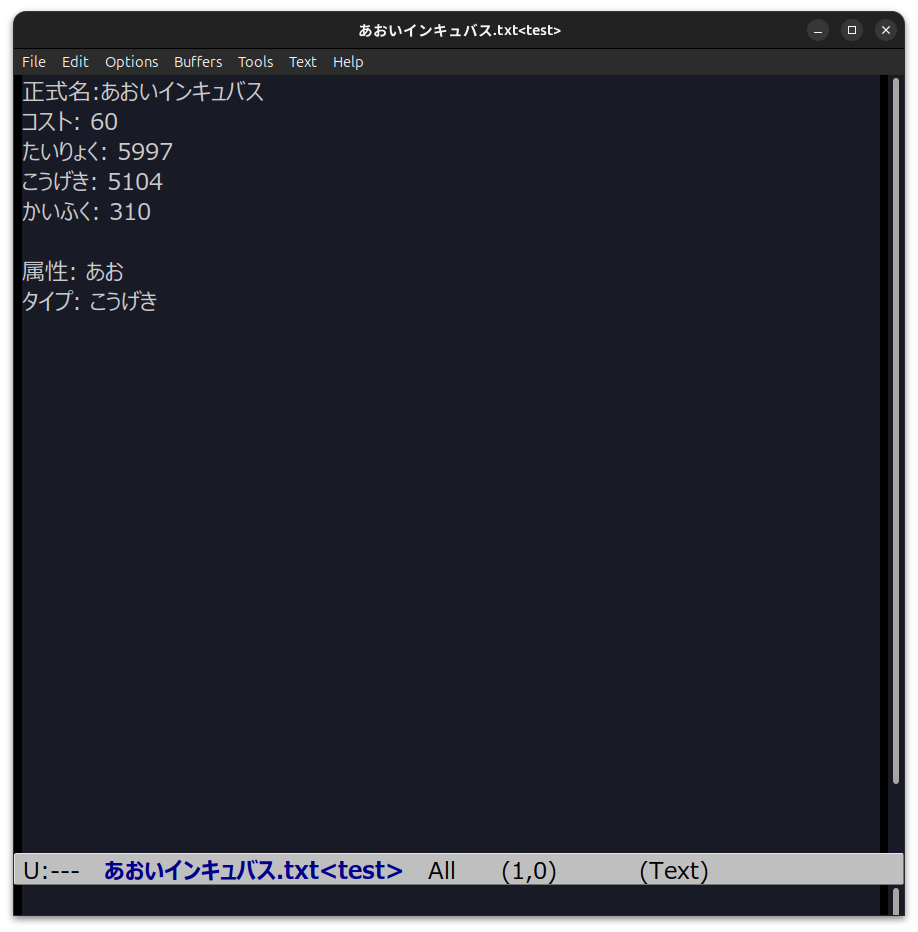
txt = f'''正式名:{name}
コスト: {cost}
たいりょく: {power}
こうげき: {attack}
かいふく: {recover}
属性: {attrib}
タイプ: {typeof}
'''
dir = 'R/'
if re.match(r'^あお', attrib):
dir = 'B/'
elif re.match(r'^みどり', attrib):
dir = 'G/'
elif re.match(r'^きいろ', attrib):
dir = 'Y/'
elif re.match(r'^むらさき', attrib):
dir = 'V/'
with open(dir + name + '.txt', "w") as f:
print(txt, file=f)
files = os.listdir("log")
for file in files:
if '.txt' in file:
get_info('log/' + file)
実行に先立って、log と 4.py のあるディレクトリに、R, B, G, Y, V というサブディレクトリを作っておく必要があります。 ここに、あか、あお、みどり、きいろ、むらさきの各キャラの詳細が .txt ファイルとして出力されます。 現状では、各キャラの詳細は「タイプ」までしか出力されません。 この後、スクリプトを修正し、もう少し多くの項目が出力されるよう、改良してみてください (python で書いておいて、後で言うのも何ですが、正規表現処理は Perl で書くほうがたぶん簡単かもしれません😅)。
テキスト処理は GUI の Windows, Mac 環境でなく、文字優先の UNIX 環境で生まれて育ちました。 ですから、テキスト処理に慣れるには、ある程度、そうした UNIX 文化を理解する必要があります。 前にも書きましたが、「テキストデータ活用術1,2」あたりが参考になると思います。 また、Perl, Python については、書き方の大枠をつかんだ後、 細かな部分をネットでノウハウでチェックし、動かしては確認するという流れになるでしょう。
参考:

コメント 記事が気に入ったらいいねしてね!  0
0  338
338

🕍 同ジャンル最新記事(-7件)
2025/09/26



2024/02/16