grep による全文検索
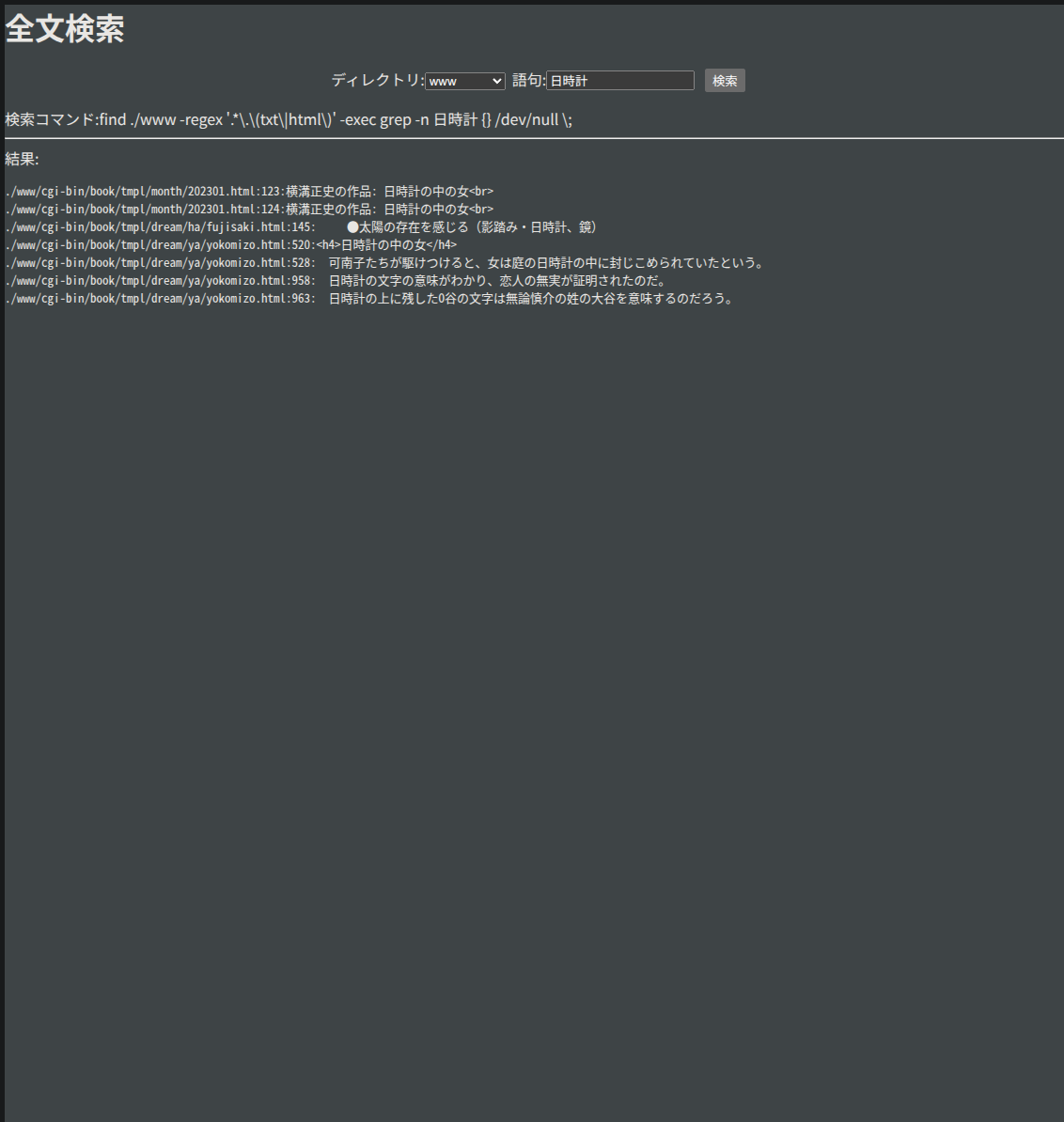
FESS などの全文検索エンジンがある一方で、検索なら昔から grep という便利なコマンドがあることが知られています。PDF 文書とか、オフィス系ファイルの中まで検索するのでなければ理論的には grep だけで済みます。grep で一体どのくらいのことができるか、試してみました。
全文検索の概略
前提として、検索対象をまず *.html(あるいは *.txt) に限定します。 さらに文字コードは UTF-8 にしておく必要があります。 ラーニング・テキスト#2 青空文庫でダウンロードしたテキストの加工1にも書きましたが、これはそう難しいことではありません。 それらが、ホームディレクトリ内の www にあるという前提で、検索してみましょう。
$ grep -nr 日時計 www --include='*.html'
このようなコードを書けばいいことになります。 結果は 1GB 程度のデータに対し 1秒以内で返ってきます。 データをテキストで貯めているならこれでもう十分実用的といえるでしょう。
WEB インターフェースをつくる
しかし、毎回、このコマンドを手で打ち、結果をコマンドプロンプトからとってくるのは面倒です。 WEB インターフェースを作りたくなります。 LAN で完結するシステムなので、CGI で十分でしょう。 そういう次第で、Python で書いてみました。 cgi モジュールは Python 3.13 から削除されていますが、 ネット上の信頼できる場所から cgi.py を取ってきて、カレントディレクトリに置けば OK です。
#!/usr/local/bin/python3
import cgi
import io, os
import sys
import subprocess
import re
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
html = '''
<html>
<!DOCTYPE HTML>
<html lang='ja'>
<head>
<title>全文検索</title>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
</head>
<body>
<h1>全文検索</h1>
<form method="post" action="" style="text-align:center">
ディレクトリ:<select name='dir'>
{opt}
</select>
語句:<input type='text' name='name' value='{name}'>
<input type='hidden' name='mode' value='confirm'>
<input type='submit' value='検索'>
</form>
検索コマンド:{command}
<hr>
結果:
<pre>
{res}
</pre>
</body>
</html>
'''
dirs = ['www', 'db']
dirname, name, command, opt, res = '', '', '', '', ''
form = cgi.FieldStorage()
if 'mode' in form:
dirname = form['dir'].value
name = form['name'].value
for key in dirs:
if key == dirname:
opt += '<option selected>' + key + '</option>\n'
command = "grep -nr " + name + " " + dirname + " --include='*.txt' --include='*.html'"
os.chdir('/ホームディレクトリ名')
res = subprocess.run(command, shell=True ,stdout=subprocess.PIPE , stderr=subprocess.PIPE ,encoding="utf-8").stdout
res = res.replace('&', '&')
res = res.replace('<', '<')
res = res.replace('>', '>')
else:
opt += '<option>' + key + '</option>\n'
print(html.format(opt=opt, name=name, command=command, res=res))
1行目の Python コマンドの位置はご自身の環境に合わせてください。 subprocess モジュールが必要なので、なければ install してください。 また、終わりに近い「ホームディレクトリ名」もご自身のものをお書きください。 総じて、UNIX 環境を前提として書いていますが、Windows, Mac でも動くはずです。
また、動作には apache などの WWW サーバ、CGI 環境が必要です。 そうした環境がないという場合、参考の「テキストデータ活用術1,2」に方法が書いてあります。
参考:

コメント 記事が気に入ったらいいねしてね!  0
0  337
337

🕍 同ジャンル最新記事(-7件)
2025/09/26



2024/02/16