Fess のインストール
.txt, .tex, pdf, Officeファイル, Libre Officeファイル, html ファイルなどを対象に インデックス化され、検索できます。 ローカルマシン、ウェブの検索、全インデックス中の限定した部分の検索などが可能。 いわゆる全文検索エンジンです。
docker 版のインストールと起動
docker 版はインストール方法が最も単純です。 まず、docker が使えるようにしておきます。 この方法は環境が変わっても、再度これをやればいいのでたぶん可搬性が最も高いでしょう。
2つのファイルを docker というディレクトリにダウンロードします。
$ mkdir docker
$ wget https://raw.githubusercontent.com/codelibs/docker-fess/master/compose/compose.yaml
$ wget https://raw.githubusercontent.com/codelibs/docker-fess/master/compose/compose-opensearch2.yaml
Fess の起動は以下のコマンドだけです。
$ docker compose -f compose.yaml -f compose-opensearch2.yaml up -d
http://localhost:8080/ にアクセスすることによって、起動を確認できます。 (ユーザー:admin, パスワード:admin。パスワードは初回変更のこと)
Fess の停止
$ docker compose -f compose.yaml -f compose-opensearch2.yaml down
Fess の削除
$ docker volume rm compose_esdata01 compose_esdictionary01 compose_esdata02 compose_esdictionary02
インデックスの作成
compose.yaml の volume セクションの restart の下あたりに
volumes:
- type: bind
source: /home/raku
target: /raku
などと書きます。
これはローカルマシンの /home/raku を docker 内に /raku という名前でマウントすることを意味します (raku は自分のユーザー名によって変える)。 ※マウントは2つまではうまくいきましたが、3つ以上はエラーになりました。
/home/raku/DB に test.txt というファイル名で、
これは fess の動作テストのためのテキストファイルですなどといった文書を作って保存します。
起動した Fess の管理画面で、 [クローラ]の[ファイルシステム]に新規の設定を作ります(例)。
名前 db
パス file:/raku/DB
クロール対象とするパス
クロール対象から除外するパス
.*\.m4v$
.*\.exe$
.*\.tgz$
.*\.wmv$
.*\.zip$
検索対象とするパス
検索対象から除外するパス
設定パラメーター
深さ
最大アクセス数
スレッド数 5
間隔 1000 ミリ秒
ブースト値 1.0
パーミッション {role}guest
仮想ホスト
状態 有効
説明 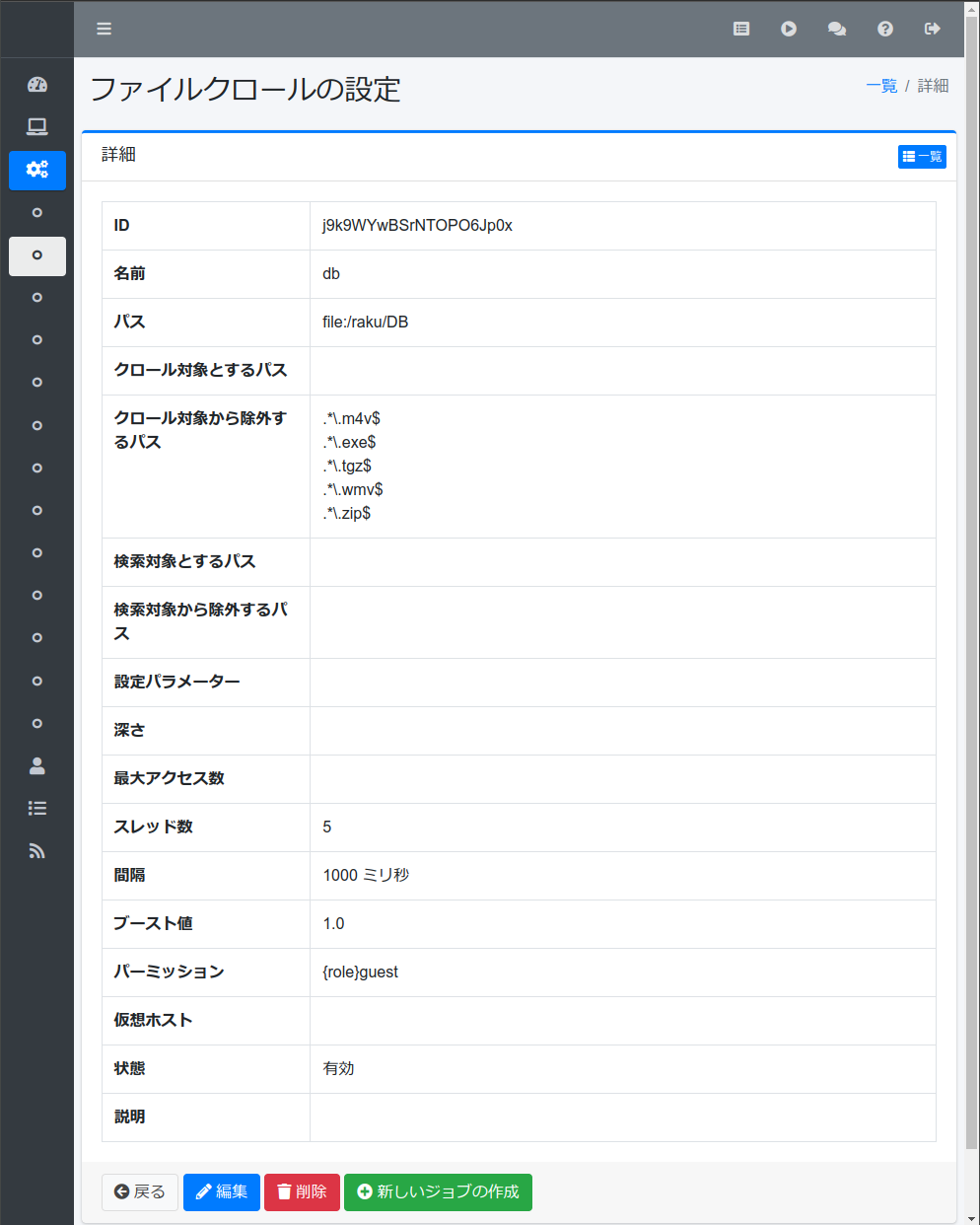
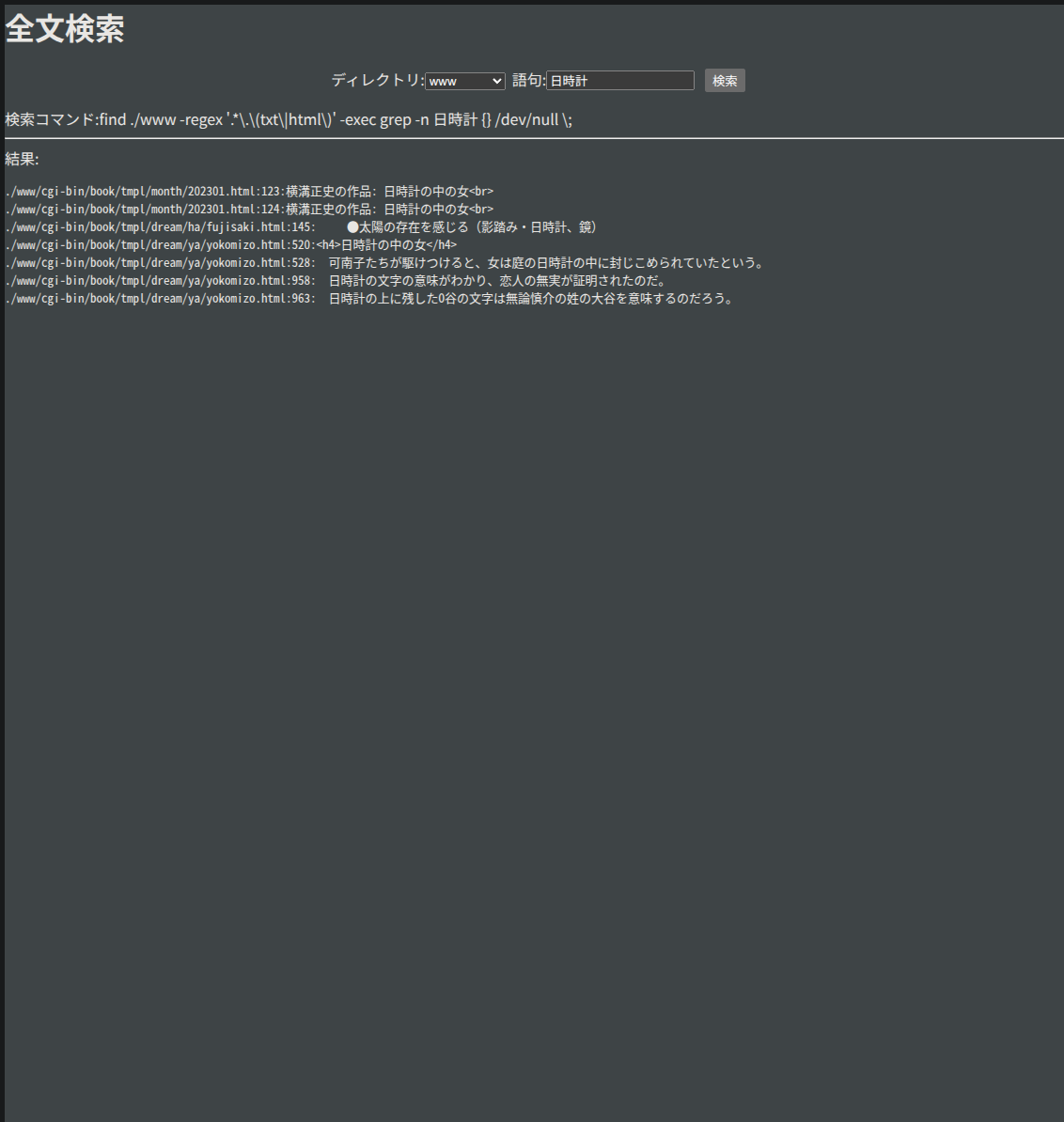
続いて、[システム]-[スケジューラー]-[Default-Crawler]と進み、 [開始]ボタンを押します。 進行状況は[システム情報]-[ジョブログ]で確認できます。 エラーは[システム情報]-[障害URL]で確認できるかもしれません。 数分たつと終わるので、管理画面の[検索]領域に * を入れ、🔍ボタンを押します。 インデックス化ができていれば、検索結果 1件中 1件目で、 test.txt が表示されるはずです。
ラベル
場所を明確にするラベルをつけてみましょう。
[クローラ]-[ラベル]とし、db というラベルを新規作成します。
名前 db
値 db
対象とするパス file\:/raku/DB/.*
除外するパス
パーミッション {role}guest
仮想ホスト
表示順序 0こんどは先刻同様[スケジューラ]の[Label Updater]を動かします。 管理画面から抜けて、トップページで 「テスト」などといった語句を詳細検索してみます。 このとき、ラベルが指定できるので、db をクリックして、選択しておきましょう。
ウェブページの検索
[クローラ]-[ウェブ]とし、localhost という名の設定を新規作成します。
名前 localhost
URL http://192.168.1.254/
クロール対象とするURL
クロール対象から除外するURL
検索対象とするURL
検索対象から除外するURL
設定パラメーター
深さ 1
最大アクセス数
ユーザーエージェント Mozilla/5.0 (compatible; Fess/14.11; +http://fess.codelibs.org/bot.html)
スレッド数 1
間隔 10000 ミリ秒
ブースト値 1.0
パーミッション {role}guest
仮想ホスト
状態 有効
説明 深さを 1 としたのはテストのためで、そうでないとページにあるリンクを次々と たどって検索してしまうからです(1なら、リンクを1度しかたどらない)。
保存したら、先程と同じように、スケジューラから Default-Crawler を動かし、 ページがインデックス化されたかを確認しましょう。
BASIC認証がかかったページの検索
もし、http://192.168.1.254/cgi-bin/data/ が BASIC 認証のかかったディレクトリだとします。 このとき、まず、localhost とは別の [ウェブ]クロール設定を作ったほうがいいでしょう。
名前 localhostBASIC
URL http://192.168.21.254/cgi-bin/data/
クロール対象とするURL http://192.168.21.254/cgi-bin/data/.*
クロール対象から除外するURL (?i).*(css|js|jpeg|jpg|gif|png|bmp|wmv|xml|ico|exe)
検索対象とするURL
検索対象から除外するURL
設定パラメーター
深さ
最大アクセス数
ユーザーエージェント Mozilla/5.0 (compatible; Fess/14.11; +http://fess.codelibs.org/bot.html)
スレッド数 3
間隔 10000 ミリ秒
ブースト値 1.0
パーミッション {role}guest
仮想ホスト
状態 有効
説明 「クロール対象から除外するURL」は最初から上のようなものが入ってくるはずです。 このサイトの全ページをインデックス化したいので深さには何も書きません。 スレッド数はデフォルトが 1で、遅く感じたら 3 にするといいでしょう。
今度は[クローラ]-[ウェブ認証]とし、以下のような新しい設定をつくります。
ホスト名 192.168.1.254
ポート 80
レルム
スキーム Basic
ユーザー名 raku
パスワード ******
パラメーター
ウェブ設定 localhostBasicユーザー名とパスワードは実際に BASIC 認証で使っているものです。 ウェブ設定は、上で作った localohostBASIC が入る必要があります。 ここまできたら、スケジューラから Default-Crawler を動かし、確認しましょう。
うまく行かない場合は、誤字脱字の類をチェックします。
その他
私のインデックス化にかかった時間は、
ファイルシステム 7700ファイル 25分(5スレッド)
ファイルシステム 130850ファイル 7時間25分(〃)
ウェブ(local BASIC) 1035ページ 65分(3スレッド)でした。 ファイルサイズは 2MB を超えるあたりが上限で、 それを超えるものはインデックス化されないようです (障害URLに表示される)。
コメント 記事が気に入ったらいいねしてね!  0
0  396
396

参考: Fess 公式ドキュメント
🕍 同ジャンル最新記事(-7件)
2025/09/26



2024/02/16